https://sampatt.com/Sam Patterson's Blog2025-02-21T23:46:51.890Zhttps://github.com/jpmonette/feedSam Pattersonhttps://sampatt.comThoughts on software development, AI, and technologyhttps://sampatt.com/favicon.icoAll rights reserved 2025, Sam Patterson<![CDATA[AI Tools Suck and are Amazing]]>https://sampatt.com/blog/2025-02-09-AI2025-02-09T00:00:00.000ZSam Pattersonhttps://sampatt.com<![CDATA[Testing Zonos TTS + Ubuntu + 4090]]>https://sampatt.com/blog/2025-02-10-zonos2025-02-10T00:00:00.000Z jsDelivr pipeline so that I could include screenshots in these blog posts easily. But I'll write about that tomorrow.)
My first test was the introductory paragraph from Winnie-the-Pooh.
It was very... meh, until 30 seconds in, when it got exciting, and by exciting, I mean it burst my eardrums.
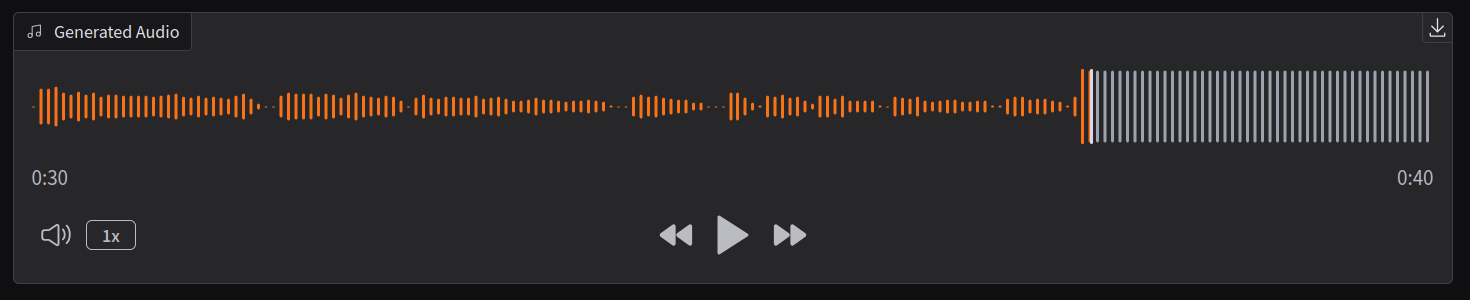
You don't need to be an audio engineer to know that a waveform probably shouldn't look like that.
So I tried again, curious to see if 30 seconds was the cutoff.
First impression: It's not all that fast. The claim is it's 2X realtime with a 4090. I've got a 4090, and... maybe? Most recently I've used Kokoro and that's way, way faster than this, not even close.
Second impression: My first impression might be wrong because it's over 300 seconds now generating a dinosaur joke I asked phi4 to make. It's probably borked somehow... yeah errors abound in terminal. It works now, and it's fairly fast too.
There's definitely a 30 cut off here. And the quality is weird.
Ok I'm wondering if there's more of an issue with the Gradio default settings, or me doing something wrong, because this isn't anywhere as good as Kokoro. I just opened up the Kokoro Gradio interface and tested the same input - Kokoro is much faster, sounds better, and doesn't choke on anything longer than 30 seconds.
### Voice cloning
At this point I'm sure I need to understand how to tune the controls to make this better, but before I spend the time, I wanted to test the voice cloning. I recorded a 20 second .wav of myself, dropped that into the section in Gradio, and then popped in the text I read.
The result was... not bad! Not great, but considering it was only 20 seconds and I haven't really gotten the hang of using this model yet, I can see why people are excited about this feature.
I'll keep a cautiously optimistic eye out on this one.]]>Sam Pattersonhttps://sampatt.com<![CDATA[Automated Screenshot Hosting with jsDelivr]]>https://sampatt.com/blog/2025-02-11-jsDelivr2025-02-21T23:46:51.883Z"
exit 1
fi
# Check file size (50MB limit for jsDelivr)
FILE_SIZE=$(stat -c %s "$MEDIA_PATH")
MAX_SIZE=$((50 * 1024 * 1024)) # 50MB in bytes
if [ "$FILE_SIZE" -gt "$MAX_SIZE" ]; then
echo "Error: File size exceeds 50MB limit for jsDelivr"
exit 1
fi
# Create directories if they don't exist
mkdir -p "$REPO_PATH/posts/$POST_NAME/$MEDIA_TYPE"
# Copy file to repo
cp "$MEDIA_PATH" "$REPO_PATH/posts/$POST_NAME/$MEDIA_TYPE/"
# Get filename
FILENAME=$(basename "$MEDIA_PATH")
# Generate markdown
JSDELIVR_URL="https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/$POST_NAME/$MEDIA_TYPE/$FILENAME"
if [ "$MEDIA_TYPE" = "image" ]; then
MARKDOWN=""
elif [ "$MEDIA_TYPE" = "audio" ]; then
MARKDOWN=""
fi
# Copy to clipboard
echo "$MARKDOWN" | xclip -selection clipboard
# Git commands
cd "$REPO_PATH"
git add "posts/$POST_NAME/$MEDIA_TYPE/$FILENAME"
git commit -m "Add $MEDIA_TYPE: $POST_NAME/$FILENAME"
git push
echo "Markdown copied to clipboard!"
echo "URL: $JSDELIVR_URL"
```
Nifty. This puts the file in the repo, adds it, commits and pushes it, then copies the jsDelivr url - in markdown format - into my clipboard so that I can just Ctrl+V into the editor where I'm writing my articles (Obsidian).
For example, here's exactly what is automatically loaded into my clipboard after using the tool for a screenshot below:
``
But how will this script trigger? I need it to only do this after a screenshot, and only when I say yes. I don't want all my screenshots posted to a public Github!
Solution? Another bash script:
```
#!/bin/bash
WATCH_DIR="screenshots/temp"
MEDIA_SCRIPT="/publish_media.sh"
LAST_POST_FILE="Scripts/.last_post_name"
# Create the file if it doesn't exist with a default value
if [ ! -f "$LAST_POST_FILE" ]; then
echo "2025-02-10-zonos" > "$LAST_POST_FILE"
fi
echo "Watching $WATCH_DIR for new screenshots..."
inotifywait -m "$WATCH_DIR" -e create -e moved_to |
while read -r directory events filename; do
if [[ "$filename" =~ .*png$ ]]; then
FULL_PATH="$WATCH_DIR/$filename"
LAST_POST=$(cat "$LAST_POST_FILE")
notify-send "New Screenshot" "Screenshot saved: $filename"
if zenity --question --text="Publish $filename to blog?"; then
NEW_POST_NAME=$(zenity --entry --title="Post Name" \
--text="Enter post name" \
--entry-text="$LAST_POST")
if [ -n "$NEW_POST_NAME" ]; then
# Save the new post name for next time
echo "$NEW_POST_NAME" > "$LAST_POST_FILE"
"$MEDIA_SCRIPT" "$NEW_POST_NAME" "$FULL_PATH" "image"
if zenity --question --text="Delete original file?"; then
rm "$FULL_PATH"
notify-send "Screenshot" "Original file deleted"
else
notify-send "Screenshot" "Original file kept"
fi
fi
fi
fi
done
```
This watches the temp screenshot directory I created specifically for this flow, and when it sees a new file, it triggers a notification. This tells me about the new screenshot, then it asks me (using zenity) if I want to publish it or not. If yes, it uses the publishing script above.
Now I don't actually want this for my main screenshot flow, it would be a bit annoying to be asked if I want to publish each time. So instead, I kept my default screenshot tool bound to the Print Screen button, but I added a new custom keyboard shortcut.
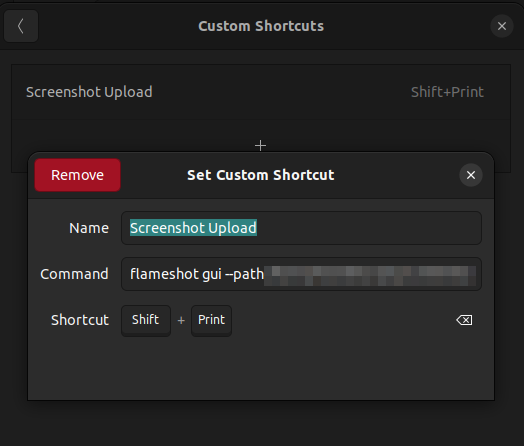
It calls `flameshot`, a screenshot tool which allows me to set a custom path for the screenshots. That way when I use `shift + Print Screen` I'll get this upload specific screenshot flow.

I tested it, and it works great. Now I need to automate this. Claude suggests an autostart entry.
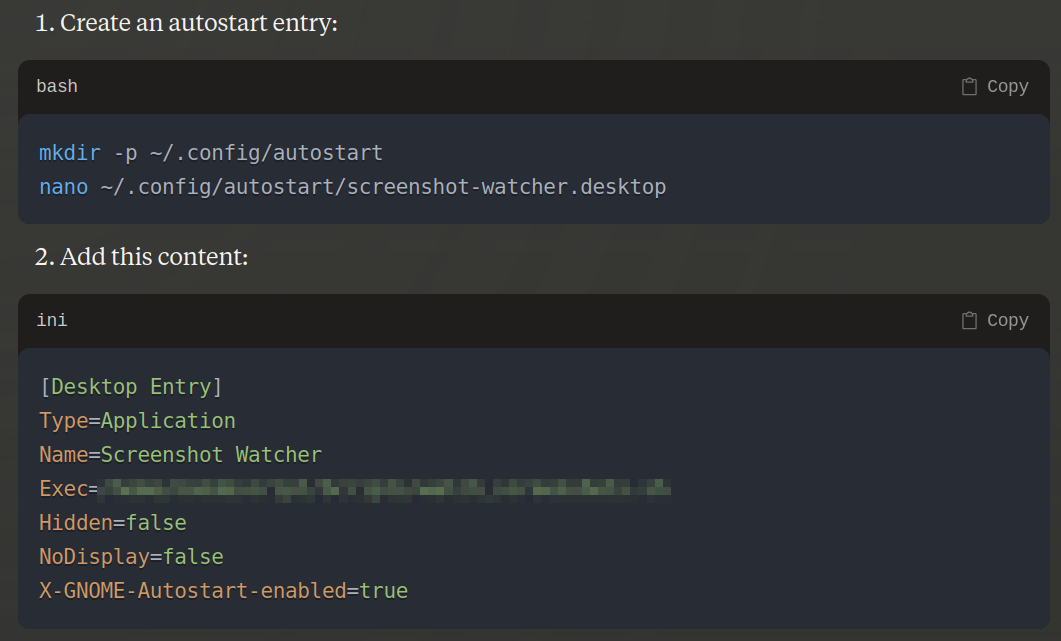
I implemented it, and now I don't need to start these scripts.
So far, it's working like a charm, it cost me $0, and it has a keyboard binding - what more could a man want?]]>Sam Pattersonhttps://sampatt.com<![CDATA[Saving My Table Tennis League’s Hard Drive—and Finding Lost BTC]]>https://sampatt.com/blog/2025-02-17-table-tennis-hard-drive2025-02-21T23:46:51.884ZSam Pattersonhttps://sampatt.com<![CDATA[Using Listmonk for my Newsletter because Substack has no API]]>https://sampatt.com/blog/2025-02-18-Listmonk2025-02-21T23:46:51.884ZSam Pattersonhttps://sampatt.com<![CDATA[Avoiding Google with Umami for Open Source Analytics]]>https://sampatt.com/blog/2025-02-19-Umami2025-02-21T23:46:51.884Z an open-source, privacy-focused web analytics tool that serves as an alternative to Google Analytics.
Sounds good to me. A few people on Reddit complained that the project team had made a few breaking changes recently, and they were annoyed at this. That worries me a little but, but in this case I'm offloading the updating process to a third party.
Only one more thing could make it perfect: is it hosted on Pikapods?
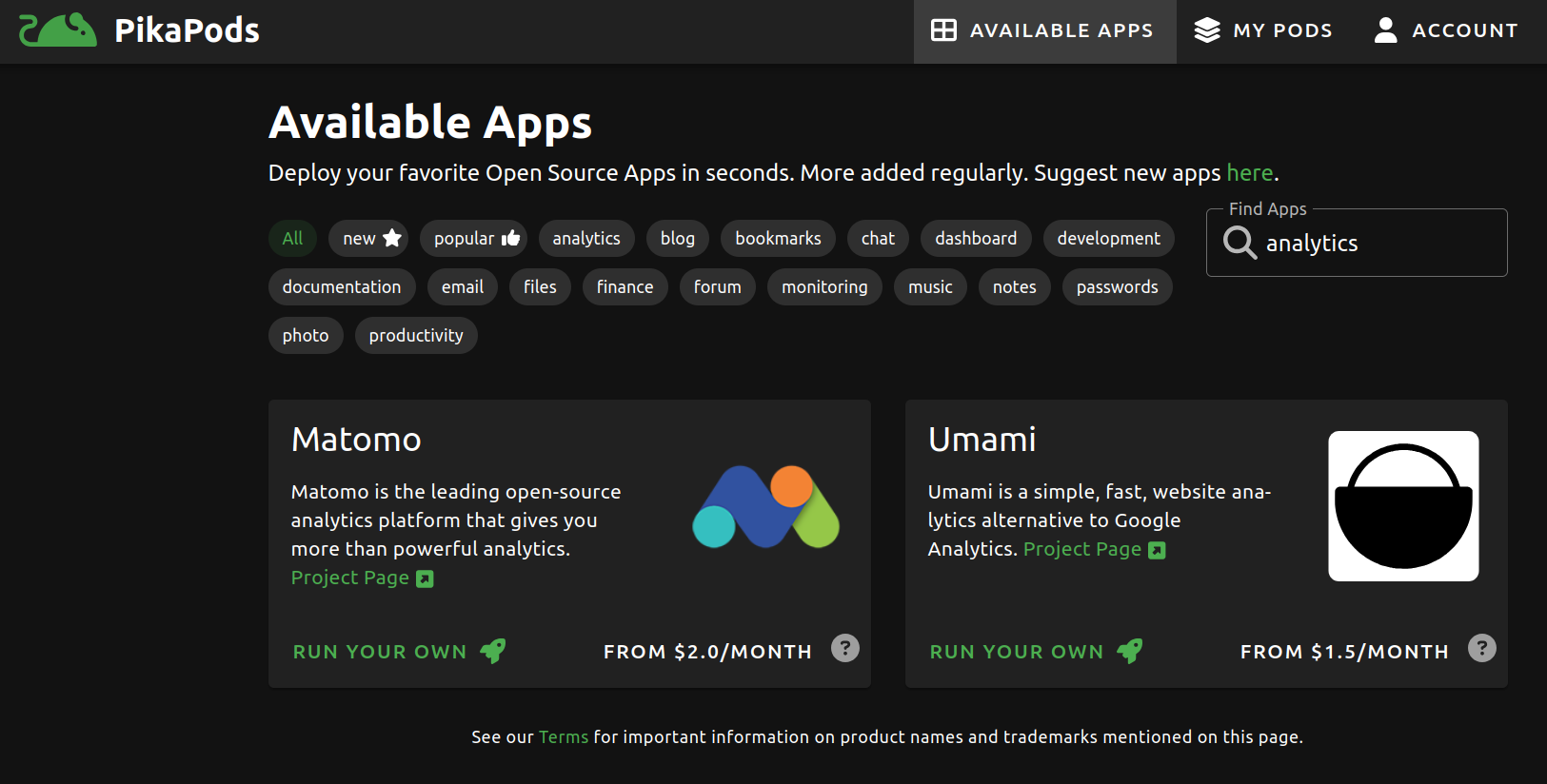
Yes! I love Pikapods so much. For dirt cheap, you pay them to host open source projects for you. I'm currently using them for Hoarder (data hoarding) and Listmonk (manages my newsletter).
I see they also offer Matomo, which I saw mentioned as a popular open source option, but my research indicated that it was heavier duty than Umami, and frankly I don't need anything special.
# Installation
Because I'm using Pikapods, the installation process consists of clicking "Add pod." 20 seconds later, I'm looking at the Umami pod interface, which is giving me a warning to:
>Immediately change the default admin details `admin` and `umami`.
The interface is simple, as promised. I changed the admin password. Also, default dark theme. Nice.
I add my website, and it tells me:
`To track stats for this website, place the following code in the ... section of your HTML.`
The code is a short one-liner with a script from my Umami instance and a website ID.
Is that it? I drop the code into my index.html, and push the changes to my Github repo.
# Testing
After it rebuilds, I check the realtime stats section on Umami. Sure enough, there I am:

That was ridiculously easy.
I planned on making a whole post about this (I guess I did). I typically ask Claude a bunch of questions about integration, etc. But this took about 15 minutes and I didn't need any help.
I'm gonna go play Geoguessr now.]]>Sam Pattersonhttps://sampatt.com<![CDATA[Fitness Tips from a Formerly Obese Nerd]]>https://sampatt.com/blog/2025-02-20-fitness-nerd2025-02-21T23:46:51.884ZSam Pattersonhttps://sampatt.com<![CDATA[No Ideology Required; AI Customization Makes Open Source Tools the Obvious Choice]]>https://sampatt.com/blog/2025-02-21-open-source-ai-customize2025-02-21T23:46:51.884ZSam Pattersonhttps://sampatt.com